技術_3D堆疊SRAM
定義
3D 堆疊 SRAM(3D-Stacked SRAM)是把 SRAM 記憶體晶片垂直堆疊在邏輯(CPU/GPU/AI 加速器)晶片正上方的封裝架構,將資料搬移距離從傳統並列擺放的數公分縮短到數十~數百微米。它與 HBM 同屬「3D 堆疊記憶體」,但 HBM 堆疊的是 DRAM,本技術堆疊的是 SRAM。
SRAM 雖然單位位元成本較高,卻具備更低延遲、可隨機存取、免刷新(no refresh)的特性。據來源論文,3D 堆疊 SRAM 的記憶體存取功耗與延遲,均可較 3D 堆疊 DRAM 低約一個數量級,因此特別適合 AI 推論這類低延遲、確定性反應需求的工作負載。
核心命題:AI 推論的真瓶頸是「搬資料」而非「算」
當 AI 模型走向低位元量化(INT8/4-bit/二值),運算本身的能耗已大幅下降,瓶頸轉移到資料搬移:
- 8-bit 加法 ≈ 0.03 pJ、8-bit 乘法 ≈ 0.2 pJ
- 但一次 64-bit DRAM 存取 ≈ 1.3–2.6 nJ(高出運算約 4 個數量級)
把記憶體拉近運算核心,是降低這筆「資料搬移稅」的結構性解法。
圖解
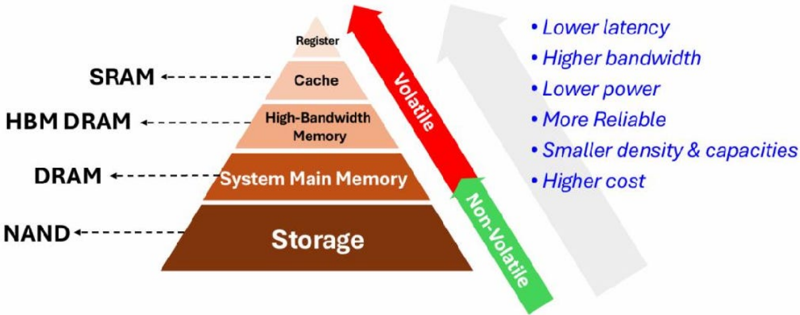
圖說:記憶體階層金字塔——愈靠近運算核心(Register/Cache/SRAM)延遲愈低、頻寬愈高、功耗愈低、成本愈高;愈往下(HBM DRAM→DRAM→NAND)容量愈大但愈慢。3D 堆疊 SRAM 的目標是把高速 SRAM 快取「做大、拉近」。

圖說:AMD Zen3 + 3D V-Cache(Ryzen 7 5800X3D)——在運算晶粒上方以 TSV 垂直堆疊 64MB SRAM,使共享 L3 快取放大到 96MB,透過 32 byte/cycle 雙向匯流排,遊戲效能提升 1.09~1.36x(來源 Wuu, ISSCC 2022),為 3D 堆疊 SRAM 的量產化驗證指標。
技術原理
傳統架構把邏輯晶片與記憶體晶片並列擺放,資料需橫向長距離傳輸。3D 堆疊把記憶體直接疊在邏輯晶片正上方,是資料流架構(dataflow)的根本重構,而不只是封裝形式的改變。
- 垂直互連:上下晶粒的連接是關鍵。傳統用 TSV(矽穿孔)+微凸塊;本來源主張的替代路線是 TCI(ThruChip Interface)近場無線互連,詳見 技術_TCI近場無線互連。
- 混合鍵合(hybrid bonding):高階路線以混合銅鍵合(HCB)做晶粒對晶粒的高密度堆疊,台積電對應平台為 技術_SoIC。
- SRAM vs DRAM 堆疊:HBM=3D 堆疊 DRAM(大容量、大頻寬);3D 堆疊 SRAM=低延遲、近運算、免刷新,兩者定位互補而非取代。
效能增益(來源引用既有研究)
| 應用 | 增益 | 說明 |
|---|---|---|
| AI 加速器 | 最高 2.1x | 近運算 SRAM 降低資料搬移瓶頸 |
| CPU(大容量快取) | 最高 1.25x | 作為大型 LLC 快取 |
| 剪枝 DNN 加速器(pruned DNN) | 最高 1.4x | 稀疏神經網路受惠 |
顯示 3D SRAM 的價值不限單一加速器類型,可延伸到 CPU 快取、稀疏網路與記憶體中心運算架構。
案例:Fujitsu MONAKA — 旗艦 3D 堆疊 SRAM CPU
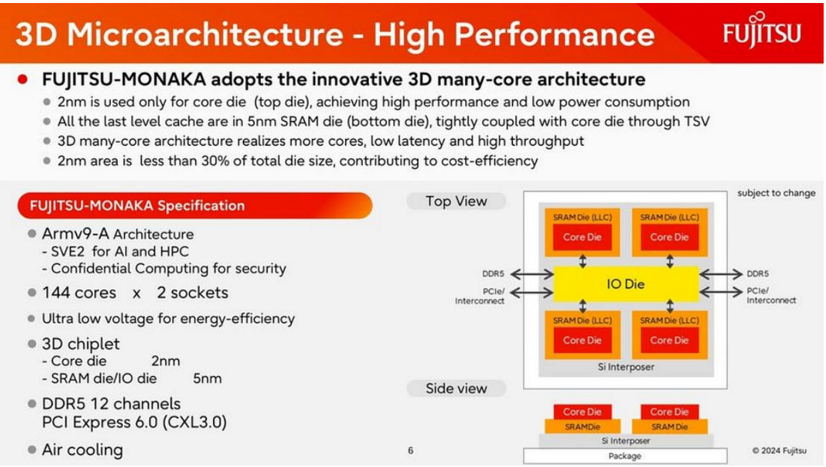
圖說:Fujitsu MONAKA 3D 微架構——中央 I/O die 周圍配置 4 組垂直堆疊 3D complex,每組為「2nm 核心晶粒(上)+ 5nm LLC SRAM 晶粒(下)」,下方以矽中介層(Si interposer)+基板整合;2nm 僅占總晶粒面積 < 30%,為成本控制核心設計。
MONAKA 是把 3D 堆疊 SRAM 落地到伺服器 CPU 的指標性架構:
- 規格:144 個 Armv9-A 核心 × 雙 socket;SVE2 向量指令(強化 AI/HPC);支援機密運算(confidential computing);DDR5 12 通道;PCIe 6.0/CXL 3.0;超低電壓設計;氣冷即可(免水冷)。
- 異質製程(cost-aware):核心晶粒用 2nm(最貴製程只用在最有價值的運算核心),LLC SRAM 晶粒與 I/O 晶粒用較成熟的 5nm。Fujitsu 稱 2nm 部分僅約占總晶粒面積 30%。
- 堆疊方式:以混合銅鍵合(HCB)face-to-face(F2F)把 2nm 運算晶粒疊在 5nm SRAM 晶粒上(部分投影片標示透過 TSV 緊耦合)。
- 效能宣稱:相較約 2027 年的競品,能效約 2 倍、應用層效能約 2 倍。
為什麼 MONAKA 「離開 HBM」

圖說:A64FX(左)vs MONAKA(右)對照——前代 A64FX(Fugaku 超算)採 2.5D + HBM2(4 通道);MONAKA 改採 3D chiplet + DDR5 12 通道,並把記憶體頻寬需求交給封裝內的 3D SRAM 快取。
因為封裝內的 3D SRAM 快取已在運算核心旁提供高內部頻寬,Fujitsu 得以降低對昂貴的封裝外 HBM 的依賴,改用成本較低的 DDR5。這不代表 HBM 變不重要,而是記憶體架構正走向「依工作負載分流」:
- GPU 訓練/大型 AI 加速器 → 仍仰賴 HBM
- CPU 中心的 AI 推論/HPC/雲端原生 → 大容量 3D SRAM 快取 + DDR5 可能在成本、功耗、容量、可擴展性上更平衡
記憶體階層定位(SemiVision 觀點)
3D SRAM 不是 HBM 的替代品,而是 AI 記憶體階層的新一層
HBM 解決 AI 訓練的高容量、高頻寬問題;on-chip SRAM 提供高速本地快取;3D 堆疊 SRAM 可能成為兩者之間的中間層——提供高頻寬、低延遲、且物理上更貼近運算核心。
六層記憶體階層(由晶片到資料中心):On-Chip SRAM →(3D 堆疊 SRAM)→ HBM → DDR/RDIMM → CXL 記憶體池 → 本地 SSD/NVMe → 物件/遠端儲存。
關鍵參數 / 判斷指標
| 指標 | 意義 | 觀察重點 |
|---|---|---|
| 堆疊互連方式 | TSV vs TCI vs 混合鍵合 | 成本、良率、頻寬、ESD(見 技術_TCI近場無線互連) |
| 快取容量 | 可堆疊的 LLC SRAM 大小 | V-Cache 96MB;MONAKA LLC 規模 |
| 異質製程切分 | 先進節點只用在核心 | MONAKA:2nm 核心僅占 ~30% 面積 |
| 記憶體存取功耗/延遲 | 相對 3D-DRAM | 約低一個數量級 |
| 工作負載適配 | 推論 vs 訓練 | 低延遲確定性 → 3D SRAM;大容量頻寬 → HBM |
技術瓶頸 / 風險
- 單位位元成本高:SRAM 密度遠低於 DRAM,大容量堆疊成本壓力大。
- 垂直互連挑戰:TSV 增加製程步驟、成本與良率風險;TCI 則面臨高密度下的串擾(crosstalk)問題(見 技術_TCI近場無線互連)。
- 散熱:運算晶粒疊在記憶體上方(或下方)後,熱密度與散熱路徑需重新設計。
- 生態系成熟度:相對 HBM 的成熟供應鏈,3D 堆疊 SRAM 在伺服器端仍屬導入期(MONAKA 約 2027 才上市)。
關鍵廠商
| 環節 | 廠商 | 角色 |
|---|---|---|
| 先進封裝/混合鍵合 | 2330_台積電(市) | SoIC 混合鍵合平台,AMD 3D V-Cache 代工 |
| CPU + 3D-SRAM 架構 | Fujitsu(MONAKA) | 旗艦 3D 堆疊 SRAM 伺服器 CPU;2nm core + 5nm SRAM |
| 處理器量產驗證 | AMD(Ryzen X3D / EPYC) | 3D V-Cache 消費級與伺服器量產先例 |
| 記憶體供應(對照層) | Samsung / SK hynix / Micron | HBM(3D 堆疊 DRAM)主要供應商 |
| TCI 互連學術來源 | 東京大學 Kuroda 實驗室 | ThruChip Interface 近場無線互連 |
| 台股利基映射 | 6531_愛普(市) | ApSRAM / VHM / WoW 近運算堆疊記憶體利基 |
應用場景
- 邊緣 AI 推論:自動駕駛、工廠自動化、即時感測等需低延遲、確定性反應的場景。
- 大型快取 CPU / HPC:MONAKA 類 CPU-中心 AI 與雲端原生工作負載。
- 稀疏 / 剪枝神經網路加速器:受惠於近運算大快取。
投資觀察 / 台股映射
台股利基標的:愛普(6531)=「廉價版 3D 堆疊 SRAM」概念類比
6531_愛普(市) 的 ApSRAM(客製化 SRAM)+ VHM(1+8Hi stack)+ WoW(wafer-on-wafer)封裝,本質上是以較低成本做「近運算的堆疊記憶體」,與本頁 hybrid bonding/TCI 高階路線的 3D 堆疊 SRAM 概念相近、定位偏利基與邊緣/AI 加速器。
- 屬「概念類比」非同一技術(thesis,中信心):愛普主攻成本敏感的客製記憶體與利基堆疊,而非高階伺服器 CPU 的 hybrid bonding LLC。
- 投資意涵:3D 堆疊 SRAM/近運算記憶體趨勢若成形,愛普是台股少數具「堆疊記憶體 + 近運算」題材的映射標的。
- 延伸論點整理於 分析_Agentic AI CPU與記憶體超級週期。
技術演進時程
gantt title 3D 堆疊 SRAM 演進 dateFormat YYYY section 消費/驗證 AMD Ryzen 3D V-Cache 量產 :done, 2022, 2024 section 伺服器導入 Fujitsu MONAKA(2nm core+5nm SRAM) :active, 2026, 2028 MONAKA-X 1.4nm(CPU) : 2029, 2030 MONAKA-X(CPU+NPU) : 2030, 2031
Fujitsu 處理器世系:SPARC64(2011)→ A64FX/Fugaku(2020,HBM2)→ MONAKA(DDR5 + 3D SRAM)。
相關技術
- 技術_TCI近場無線互連(垂直互連替代 TSV 的路線)
- 技術_TSV(傳統垂直互連)
- 技術_SoIC(混合鍵合 3D 堆疊平台)
- 技術_HBM(3D 堆疊 DRAM,互補對照層)
- 技術_CoWoS(2.5D 先進封裝)
來源
- 產業_SEMIVISION_3D堆疊SRAM_20260520,SemiVision Research,2026-05-20(capture)
- 原始論文群:東京大學 Kuroda 實驗室 TCI;AMD 3D V-Cache(Wuu, ISSCC 2022);Fujitsu MONAKA 架構公開資料